Following the previous article ITX Host Upgrade + Dust Cleaning Record which involved hardware maintenance, I recently optimized the home streaming service Jellyfin from a software perspective, turning Jellyfin into a true NAS. It is not only used for watching movies and series but also for storing family pictures, videos, books, and podcasts.
NAS is defined on Wikipedia as: Network-attached storage (NAS) is a file-level (as opposed to block-level storage) computer data storage server connected to a computer network providing data access to a heterogeneous group of clients. The term "NAS" can refer to both the technology and systems involved, or a specialized device built for such functionality (as unlike tangentially related technologies such as local area networks, a NAS device is often a singular unit).
Translation: Network-attached storage (NAS) is a file-level (as opposed to block-level storage) computer data storage server that connects to a computer network, providing data access to a heterogeneous group of clients. The term "NAS" can refer to both the technology and systems involved, or a specialized device built for such functionality (unlike related technologies such as local area networks, a NAS device is often a singular unit).
So, unlike the NAS devices we commonly refer to, software or systems that achieve the corresponding functionality can also be called NAS. For example, my NAS runs on a Win11 host that is powered on 24/7. Therefore, this article is based on the Win11 environment for configuration.
Deployment Plan#
Nastools + Jackett + Qbittorrent + ChineseSubFinder + Jellyfin
All of the above services can be directly deployed on Windows.
Functionality#
- Use Jackett to index BT sites and feedback to Nastools for scraping movies and shows (variety shows, dramas, anime) using the TMDB API (I am a BT enthusiast and do not have the energy to mess with PT, but the built-in indexer websites in NASTools are few, mainly anime sites, which cannot meet the needs of film and television, so Jackett is introduced to increase the index sites).
- Use NASTools and Qbittorrent tools to batch download and organize media files.
- Use ChineseSubFinder to automatically download Chinese subtitles.
- Hardware transcoding to accelerate media playback.
The specific deployment method is not the focus of this article; there are plenty of tutorials available online for reference. I will share some advanced operations in hopes of helping more people.
Hard Link🔗#
For specific methods of moving files such as hard links, soft links, etc., you can refer to Terminology Explanation - Transfer Methods.
We can easily implement hard links using NASTools, but sometimes due to the file naming of anime subtitle groups or unrelated files, metadata cannot be recognized. Therefore, manual intervention is needed. Here, I wrote a script in Python to achieve automation.
Directory structure:
[DBD-Raws][K-On!][01-12TV Series + Special Features][1080P][BDRip][HEVC-10bit][Simplified and Traditional Subtitle][FLAC][MKV]
├── CDs
│ ├── 01
│ │ ├── 01 Fluffy.flac
│ │ ├── 02 I Will Do My Best in the Next Life.flac
import os
# Create hard links for all files in a directory to another directory
def create_hard_links(folder, new_folder):
# If the main anime folder does not exist, create it
while not os.path.exists(new_folder):
os.mkdir(new_folder)
# Iterate through all files in the folder
for file_name in os.listdir(folder):
try:
file_path = os.path.join(folder, file_name)
# If it is a folder, recursively call the function
if os.path.isdir(file_path):
# Also create that folder, because hard links cannot link folders
new_folder_path = os.path.join(new_folder, file_name)
os.mkdir(new_folder_path)
create_hard_links(file_path, new_folder_path)
else:
new_file_path = os.path.join(new_folder, file_name)
# If the file already exists, add the suffix “_copy{n}”, for example, if there are multiple “cover.jpg”, name them “cover_copy1.jpg”, “cover_copy2.jpg”, etc.
while os.path.exists(new_file_path):
print(f"Renaming {file_name} to add the suffix “_copy” in {new_folder}")
count = 1
file_name_without_extension, file_extension = os.path.splitext(file_name)
new_file_name = f"{file_name_without_extension}_copy{count}{file_extension}"
count += 1
new_file_path = os.path.join(new_folder, new_file_name)
os.link(file_path, new_file_path)
print(f"Link created successfully! Go check it out in {anime_dir} o(* ̄▽ ̄*)ブ!")
except (FileNotFoundError, PermissionError) as e:
print(f"An error occurred: {str(e)}")
# Usage example
anime_name="K-On! (2020) 1"
# NASTools set secondary directory
category = ["Anime", "Completed Anime"]
# suffix = "CDs"
anime_dir = f"D:\TV\Anime\{category[1]}\{anime_name}"
# os.mkdir(anime_dir)
source_folder = r'D:\Media_download\[DBD-Raws][K-On!][01-12TV Series + Special Features][1080P][BDRip][HEVC-10bit][Simplified and Traditional Subtitle][FLAC][MKV]\Fonts'
new_folder = rf'{anime_dir}'
create_hard_links(source_folder, new_folder)
Script download🔗:hlink.py
Subtitle Optimization#
Custom Subtitles#
【Console】->【Playback】->【Backup Font File Path】, check 【Enable Backup Font】.
Format Conversion#
Since the fonts provided by subtitle groups are mostly .otf, .ttf, etc., their file sizes can be as large as 27MB, which is quite a burden for WEB transmission. Referring to the Jellyfin official documentation, we know that we can use .woff2 format, which is an efficient font compression format specifically used in web development. It can be compressed to about 50% of the original size. We use fontTools and Google’s Brotli compression algorithm for batch font conversion. Compared to traditional compression algorithms (like gzip), Brotli can achieve faster decompression speeds at the same compression ratio.
Translation: The web client currently uses the Fallback Fonts option to render subtitles only. This can be set to a folder containing fonts for this purpose. These fonts have a total size limit of 20MB. Lightweight formats optimized for the web, such as woff2, are recommended.
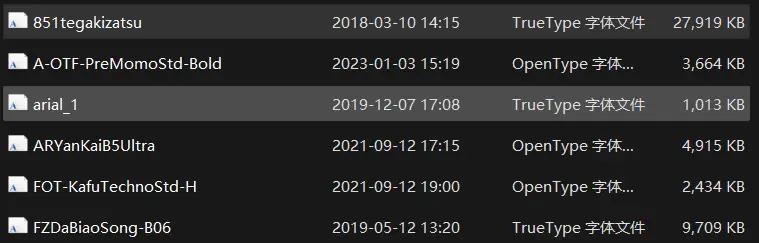 Before Compression
Before Compression
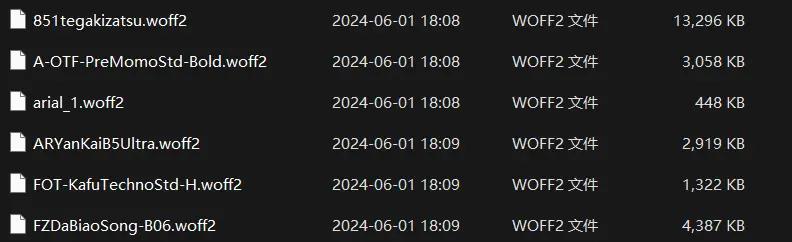 After Compression
After Compression
The conversion script is as follows:
from fontTools.ttLib import TTFont
import brotli
import os
def convert_fonts_in_directory(input_dir):
for file in os.listdir(input_dir):
if os.path.isdir(os.path.join(input_dir, file)):
convert_fonts_in_directory(os.path.join(input_dir, file))
elif file.lower().endswith((".otf", ".ttf")):
input_file = os.path.join(input_dir, file)
output_file = os.path.join(output_dir, os.path.splitext(file)[0] + ".woff2")
convert_otf_to_woff2(input_file, output_file)
else:
print(f"The file {file} is not an .otf/.ttf file.")
def convert_otf_to_woff2(input_file, output_file):
font = TTFont(input_file)
font.save(output_file, 'woff2')
with open(output_file, 'rb') as f:
woff2_data = f.read()
compressed_data = brotli.compress(woff2_data)
with open(output_file, 'wb') as f:
f.write(compressed_data)
print(f'Conversion successful, they are quietly waiting for you in {output_dir} (*^▽^*)!')
# Input and output directories
input_dir = r'D:\File Transfer\Fonts\1'
output_dir = r'D:\File Transfer\Fonts\1'
# Call the function to perform conversion
convert_fonts_in_directory(input_dir)
Script download🔗:convert_to_woff2.py
After converting the format, the fonts can basically meet the needs. If further compression is needed, please refer to Font Subsetting.
Episode Display Order#
When scraping special files for anime, there may be cases where the structure of TMDB metadata differs from the naming order of subtitle groups, leading to scraping failures. For example, "In Any Case, It's Very Cute - High School Girl Edition" is placed in episodes 16-19 of the special features on TMDB.
While the structure of the Yunguang subtitle group is as follows👇
We have two solutions for this:
- Rename to S00E16-S00E19 for scraping.
- Understand the TMDB Episode Group metadata.
In Jellyfin, corresponding settings can be made: select the episode -> edit metadata to achieve scraping.
You can also use the TMDB API to obtain it for easy manual editing.
GET
https://api.themoviedb.org/3/tv/{series_id}/episode_groups
Podcast Scraping#
Jellyfin does not have a Podcast category, but we can achieve it through the music library or book library. However, the corresponding metadata scraping may be relatively limited, but it's better than nothing, hhh.
Once the directory structure is established, Jellyfin will automatically scrape. For example, the latest episode of BBC Sound "Trump Trial… Donald Found Guilty!" can be structured in the music library as Music - Some Artist - Album a - music.mp3.
Currently, I have not found a good plugin for scraping podcasts. NASTools only supports scraping for movies and series. If you have recommendations, please let me know to provide materials for future articles (just kidding).