继上一篇 ITX 主机升级 + 清灰记录 进行了硬件层面的维护,最近从软件层面对家庭流媒体服务 Jellyfin 做了优化,使 Jellyfin 变成一个真正意义上的 NAS,不仅用于观影和追番,还可以进行家庭图片、视频以及书籍、Podcast 等的存储。
NAS 在维基百科是这么定义的:Network-attached storage (NAS) is a file-level (as opposed to block-level storage) computer data storage server connected to a computer network providing data access to a heterogeneous group of clients. The term "NAS" can refer to both the technology and systems involved, or a specialized device built for such functionality (as unlike tangentially related technologies such as local area networks, a NAS device is often a singular unit).
翻译:网络附加存储 (NAS) 是一种文件级 (相对于块级存储) 计算机数据存储服务器,它连接到计算机网络,为异构客户端组提供数据访问。术语 “NAS” 既可以指所涉及的技术和系统,也可以指为这种功能构建的专用设备 (与局域网等相关技术不同,NAS 设备通常是单个单元)。
所以不像我们常说的 NAS 设备,实现了对应功能的软件或系统也可以这样称呼,比如我的 NAS 就是运行在一台 24h 开机的 Win11 主机上。所以本文是基于 Win11 环境进行配置
部署方案#
Nastools + Jackett + Qbittorent + ChineseSubFinder + Jellyfin
上述所有服务都可以直接部署在 windows 上
实现功能#
- 使用 Jackett 进行 BT 站索引,并反馈给 Nastools 进行电影、节目(综艺、电视剧、番剧)利用 TMDB API 刮削(我是 BT 爱好者,没有精力折腾 PT,但 NASTools 内置的索引器网站很少,主要是番剧站点,不能满足影视的需求,所以引入 Jackett 增加索引站点)
- 利用 NASTools、、Qbittorrent 工具批量下载和整理媒体文件
- 使用 ChineseSubFinder 自动下载中文字幕
- 硬件转码加速媒体播放
具体的部署方法不是这篇文章的重点,网络上有大量的教程可以参考,我分享一些进阶操作,希望能帮助更多的人。
硬链接🔗(Hard Link)#
具体关于文件的移动方式如硬链接、软链接等等概念可以参考 名词解释 - 转移方式
我们可以轻松地用 NASTools 实现硬链接,但是有时会因为番剧字幕组的文件命名或无关文件导致无法识别出元数据,所以这里就需要手动进行,这里我用 Python 写了个脚本,也是为了自动化理念的实现。
目录结构:
[DBD-Raws][孤独摇滚!][01-12TV全集+特典映像][1080P][BDRip][HEVC-10bit][简繁外挂][FLAC][MKV]
├── CDs
│ ├── 01
│ │ ├── 01 ふらふら.flac
│ │ ├── 02 来世でがんばります.flac
import os
# 创建一个目录中的所有文件的硬链接到另一个目录
def create_hard_links(folder, new_folder):
# 如果番剧主文件夹不存在,创建一个
while not os.path.exists(new_folder):
os.mkdir(new_folder)
# 遍历文件夹中的所有文件
for file_name in os.listdir(folder):
try:
file_path = os.path.join(folder, file_name)
# 如果是文件夹,递归调用函数
if os.path.isdir(file_path):
# 同时创建该文件夹,因为硬链接不能链接文件夹
new_folder_path = os.path.join(new_folder, file_name)
os.mkdir(new_folder_path)
create_hard_links(file_path, new_folder_path)
else:
new_file_path = os.path.join(new_folder, file_name)
# 如果文件已经存在,添加后缀“_copy{n}”,比如有多个“cover.jpg”,命名为“cover_copy1.jpg”,“cover_copy2.jpg”等
while os.path.exists(new_file_path):
print(f"Renaming {file_name} to add the suffix “_copy” in {new_folder}")
count = 1
file_name_without_extension, file_extension = os.path.splitext(file_name)
new_file_name = f"{file_name_without_extension}_copy{count}{file_extension}"
count += 1
new_file_path = os.path.join(new_folder, new_file_name)
os.link(file_path, new_file_path)
else:
os.link(file_path, new_file_path)
print(f"链接成功!快去{anime_dir}看看吧o(* ̄▽ ̄*)ブ!")
except (FileNotFoundError, PermissionError) as e:
print(f"An error occurred: {str(e)}")
# Usage example
anime_name="孤独摇滚(2020)1"
# NASTools设置的二级目录
category = ["动漫" , "完结动漫"]
# suffix = "CDs"
anime_dir = f"D:\TV\Anime\{category[1]}\{anime_name}"
# os.mkdir(anime_dir)
source_folder = r'D:\Media_download\[DBD-Raws][孤独摇滚!][01-12TV全集+特典映像][1080P][BDRip][HEVC-10bit][简繁外挂][FLAC][MKV]\Fonts'
new_folder = rf'{anime_dir}'
create_hard_links(source_folder, new_folder)
脚本下载🔗:hlink.py
字幕优化#
自定义字幕#
【控制台】->【播放】->【备用字体文件路径】,勾选【启用备用字体】
格式转换#
由于字幕组提供的字体多为.otf,.ttf 等,他们的文件大小最大的甚至在 27MB 左
右,这对于 WEB 传输可以说是相当大的负担了,参考 Jellyfin 官方文档我们知
道可以使用.woff2 格式,这是一种专用于 Web 开发中使用的高效的字体压缩
格式,经实测可以压缩到原来的 50%, 我们使用 fontTools,采用 Google 的
Brotli 压缩算法进行批量字体转换,相比传统的压缩算法(如 gzip),Brotli 在
相同的压缩比下可以实现更快的解压缩速度。
翻译:Web 客户端当前仅使用 Fallback Fonts 选项来呈现字幕。可以将其设置为包含字体的文件夹。这些字体的总大小限制为 20MB。建议使用 woff2 等针对 web 优化的轻量级格式。
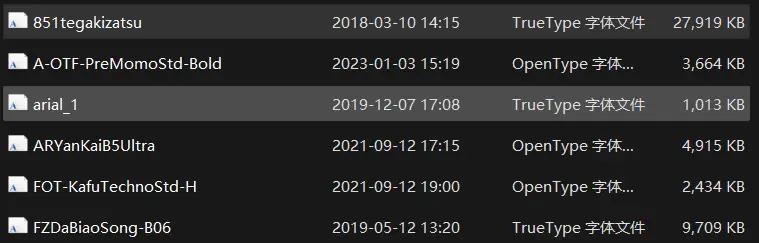 压缩前
压缩前
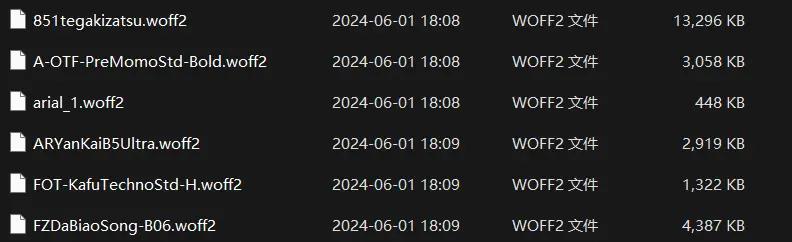 压缩后
压缩后
转换脚本如下
from fontTools.ttLib import TTFont
import brotli
import os
def convert_fonts_in_directory(input_dir):
for file in os.listdir(input_dir):
if os.path.isdir(os.path.join(input_dir, file)):
convert_fonts_in_directory(os.path.join(input_dir, file))
# 如果文件后缀是.otf/.ttf
elif file.lower().endswith((".otf", ".ttf")):
input_file = os.path.join(input_dir, file)
output_file = os.path.join(output_dir, os.path.splitext(file)[0] + ".woff2")
convert_otf_to_woff2(input_file, output_file)
else:
print(f"文件{file}不是.otf/.ttf文件")
def convert_otf_to_woff2(input_file, output_file):
# 打开 字体文件
font = TTFont(input_file)
# 将字体保存为 .woff2 文件
font.save(output_file, 'woff2')
# 压缩 .woff2 文件
with open(output_file, 'rb') as f:
woff2_data = f.read()
compressed_data = brotli.compress(woff2_data)
# 将压缩后的数据保存为 .woff2 文件
with open(output_file, 'wb') as f:
f.write(compressed_data)
print(f'转换成功,他们在{output_dir}静悄悄地等你了哦!(*^▽^*)')
# 输入和输出目录
input_dir = r'D:\文件互传\Fonts\1'
output_dir = r'D:\文件互传\Fonts\1'
# 调用函数进行转换
convert_fonts_in_directory(input_dir)
脚本下载🔗:convert_to_woff2.py
经过转换格式,字体基本就可以满足需求了,如果还需进一步压缩,请参考 字体子集化
剧集展示顺序#
在刮削番剧的特典文件时,有可能会出现因为 TMDB 元数据的结构与字幕组
命名顺序不同导致刮削失败,比如《总之就是非常可爱 - 女子高中生篇》在
TMDB 放在特典篇的 16-19 集
而云光字幕组的结构是这样👇
对此我们有 2 个解决方案
- 重命名为 S00E16-S00E19,进行刮削
- 通过了解 TMDB🈶剧集组 (Episode Group) 的元数据
在 Jeltfin 中对应设置:选中剧集 -> 编辑元数据,即可实现刮削
也可以通过 TMDB API 来获取,方便手动编辑
GET
https://api.themoviedb.org/3/tv/{series_id}/episode_groups
Podcast 刮削#
Jellyfin 没有 Podcast 分类,但是我们可以通过音乐库或者书籍库来实
现,但是对应的元数据刮削有可能比较少,不过聊胜于无 hhh。
建立好目录结构,Jellyfin 就会自动刮削,比如 BBC Sound 中的
Americast 最新一期 “Trump Trial… Donald Found Guilty!”,音乐
库结构推荐为 Music - Some Artist - Album a - music.mp3
目前还没有找到比较好刮削 Podcast 的插件,NASTools 只支持电影和剧集的刮削,
如果有推荐可以告诉我,为后续谁文章提供材料 (bushi)